PouchDB and CouchDB were designed for one main purpose: sync. Jason Smith has a great quote about this:
The way I like to think about CouchDB is this: CouchDB is bad at everything, except syncing. And it turns out that's the most important feature you could ever ask for, for many types of software."
When you first start using CouchDB, you may become frustrated because it doesn't work quite like other databases. Unlike most databases, CouchDB requires you to manage revisions (_rev), which can be tedious.
However, CouchDB was designed with sync in mind, and this is exactly what it excels at. Many of the rough edges of the API serve this larger purpose. For instance, managing your document revisions pays off in the future, when you eventually need to start dealing with conflicts.
CouchDB sync has a unique design. Rather than relying on a master/follower architecture, CouchDB supports a multi-master architecture. You can think of this as a system where any node can be written to or read from, and where you don't have to care which one is the "master" and which one is the "follower." In CouchDB's egalitarian world, every citizen is as worthy as another.
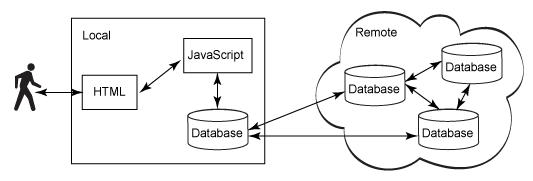
(Thanks to IBM for the image: http://www.ibm.com/developerworks/library/wa-couchdb/)
When you use PouchDB, CouchDB, and other members of the Couch family, you don't have to worry which database is the "single source of truth." They all are. According to the CAP theorem, a database can only have at most 2 of 3 properties: Consistency, Availability, or Partition-Tolerance. Typical relational databases such as MySQL are CP, which means they are consistent and tolerant to node partitions, at the expense of availability. CouchDB is an AP database, meaning that it's Partition-Tolerant, every node is Available at all times, but it's only eventually Consistent.
To illustrate, imagine a multi-node architecture with CouchDB servers spread across several continents. As long as you're willing to wait, the data will eventually flow from Australia to Europe to North America to wherever. Users around the world running PouchDB in their browsers or Couchbase Lite/Cloudant Sync in their smartphones experience the same privileges. The data won't show up instantaneously, but depending on the Internet connection speed, it's usually close enough to real-time.
In cases of conflict, CouchDB will choose an arbitrary winner that every node can agree upon deterministically. However, conflicts are still stored in the revision tree (similar to a Git history tree), which means that app developers can either surface the conflicts to the user, or just ignore them.
In this way, CouchDB replication "just works."
As you already know, you can create either local PouchDBs:
const localDB = new PouchDB('mylocaldb')
or remote PouchDBs:
const remoteDB = new PouchDB('http://localhost:5984/myremotedb')
This pattern comes in handy when you want to share data between the two.
The simplest case is unidirectional replication, meaning you just want one database to mirror its changes to a second one. Writes to the second database, however, will not propagate back to the master database.
To perform unidirectional replication, you simply do:
localDB.replicate.to(remoteDB).on('complete', function () {
// yay, we're done!
}).on('error', function (err) {
// boo, something went wrong!
});
Congratulations, all changes from the localDB have been replicated to the remoteDB.
However, what if you want bidirectional replication? You could do:
localDB.replicate.to(remoteDB);
localDB.replicate.from(remoteDB);
However, to make things easier for your poor tired fingers, PouchDB has a shortcut API:
localDB.sync(remoteDB);
These two code blocks above are equivalent. And the sync API supports all the same events as the replicate API:
localDB.sync(remoteDB).on('complete', function () {
// yay, we're in sync!
}).on('error', function (err) {
// boo, we hit an error!
});
Live replication (or "continuous" replication) is a separate mode where changes are propagated between the two databases as the changes occur. In other words, normal replication happens once, whereas live replication happens in real time.
To enable live replication, you simply specify {live: true}:
localDB.sync(remoteDB, {
live: true
}).on('change', function (change) {
// yo, something changed!
}).on('error', function (err) {
// yo, we got an error! (maybe the user went offline?)
});
However, there is one gotcha with live replication: what if the user goes offline? In those cases, an error will be thrown and replication will stop.
You can allow PouchDB to automatically handle this error, and retry until the connection is re-established, by using the retry option:
localDB.sync(remoteDB, {
live: true,
retry: true
}).on('change', function (change) {
// yo, something changed!
}).on('paused', function (info) {
// replication was paused, usually because of a lost connection
}).on('active', function () {
// replication was resumed
}).on('error', function (err) {
// totally unhandled error (shouldn't happen)
});
This is ideal for scenarios where the user may be flitting in and out of connectivity, such as on mobile devices.
Sometimes, you may want to manually cancel replication – for instance, because the user logged out. You can do so by calling cancel() and then waiting for the 'complete' event:
const syncHandler = localDB.sync(remoteDB, {
live: true,
retry: true
});
syncHandler.on('complete', function (info) {
// replication was canceled!
});
syncHandler.cancel(); // <-- this cancels it
The replicate API also supports canceling:
const replicationHandler = localDB.replicate.to(remoteDB, {
live: true,
retry: true
});
replicationHandler.on('complete', function (info) {
// replication was canceled!
});
replicationHandler.cancel(); // <-- this cancels it
One thing to note about replication is that it tracks the data within a database, not the database itself. If you destroy() a database that is being replicated to, the next time the replication starts it will transfer all of the data again, recreating the database to the state it was before it was destroyed. If you want the data within the database to be deleted you will need to delete via remove() or bulkDocs(). The pouchdb-erase plugin can help you remove the entire contents of a database.
Any PouchDB object can replicate to any other PouchDB object. So for instance, you can replicate two remote databases, or two local databases. You can also replicate from multiple databases into a single one, or from a single database into many others.
This can be very powerful, because it enables lots of fancy scenarios. For example:
- You have an in-memory PouchDB that replicates with a local PouchDB, acting as a cache.
- You have many remote CouchDB databases that the user may access, and they are all replicated to the same local PouchDB.
- You have many local PouchDB databases, which are mirrored to a single remote CouchDB as a backup store.
The only limits are your imagination and your disk space.
POST directly to the CouchDB _replicate endpoint, as described in the CouchDB replication guide.
Now that we have a grasp on replication, let's talk about an inconvenient fact of life: conflicts.




