
By: Nolan Lawson
Published: 26 October 2014
By: Nolan Lawson
Published: 26 October 2014
In the spirit of Paul Irish, here's a list of some surprising things I learned while reading (and writing) the PouchDB source code.
To set the stage: I first joined the project around December of last year, at which point PouchDB was already fairly mature. (The first commit from Mikeal Rodgers is already 4 years old!) My own background was mostly in Android development, but I had some knowledge of Web SQL thanks to a PhoneGap app I had worked on.
The main goals I had with PouchDB were to increase its performance and browser compatibility. And having dealt with that ugly F-word that haunts the Android ecosystem ("fragmentation"), I figured compatibility in the web dev world couldn't be much worse. Could it?
Warning: graphic content ahead. If you've ever been a soldier on the front lines of the browser compatibility war, the following may make you relive some of those past horrors. Be prepared to weep.
Also, if you're not familiar with LocalStorage, Web SQL, or IndexedDB, you may want to read up on those first.
When you open a Web SQL database, you use openDatabase(), e.g.:
var db = openDatabase('documents', '1.0', 'some description', 5000000);
That last parameter is the so-called estimated size. And here's how we set it in PouchDB:
function getSize(opts) {
/* ... */
var isAndroid = /Android/.test(window.navigator.userAgent);
return isAndroid ? 5000000 : 1;
}
User agent sniffing! Yes, we should be ashamed of ourselves. But here's why we do it:
For the record, here's what the dreaded Safari popup looks like:
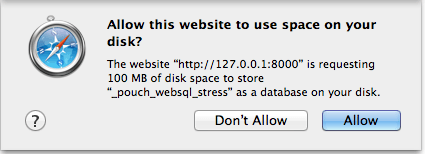
So that's why we sniff for Android and only bump the size to 5000000 in those cases. In all other cases, we set it to 1.
Additionally, the W3C has done everyone a disservice by using 5*1024*1024 in their sample code, because this has no relation to the 5MB limit in iOS/Safari. The actual cutoff to avoid the popup is 5000000 (i.e. 5 megabytes, aka 5MB), not 5*1024*1024 (5 mebibytes, aka 5MiB). And yet, if you read blog posts and Stack Overflow comments about Web SQL, you'll see the mistaken 1024*1024 repeated all over the place.
Microsoft has a very fast implementation of IndexedDB – it's a bit slower than Chrome's, but much faster than Firefox's (here are some tests). However, to get that speed, they must have taken some shortcuts, because both IE10 and IE11 have some nasty race conditions.
Due to that, you'll often see PouchDB code like this:
//Close open request for "name" database to fix ie delay.
if (IdbPouch.openReqList[name] && IdbPouch.openReqList[name].result) {
IdbPouch.openReqList[name].result.close();
}
Or code like this, where we ensure all "open" and "destroy" operations on the databases are done sequentially:
taskQueue.queue.push({
action: function (thisCallback) {
destroy(name, opts, thisCallback);
},
callback: callback
});
Or code like this, where we keep a cache of all databases by name, since IE will not allow us to open two databases with the same name at the same time:
var cached = cachedDBs[name];
if (cached) {
idb = cached.idb;
/* ... */
}
To their credit, though, the IE team has been very responsive to our bug reports, so this might be fixed soon.
At the time the Web SQL spec was hammered out, nothing like Blobs or ArrayBuffers had been standardized. SQLite of course has support for the binary BLOB type, but in order to store binary data in WebSQL, you need to do it the old-fashioned way, and pass in a JavaScript binary string.
This produces two interesting problems:
\u0000 character is treated as a null terminator, and although you can insert and sort on the full string, when you retrieve it, it will be truncated. And since BLOBs must be inserted as binary strings, this means any binary data containing the 0 byte will be truncated. The only workaround is to use SELECT HEX(columnName), which returns the full binary data in hexadecimal format.HEX() presents its own problems, because Safari < 7.1 and iOS < 8 coerce all strings to UTF-16, meaning that the hexadecimal format must be parsed differently in UTF-8 browsers (Chrome/Opera/Android as well as modern Safari/iOS) vs. UTF-16 browsers (early Safari/iOS).Thus you will see fun code like this:
function parseHexString(str, encoding) {
var result = '';
var charWidth = encoding === 'UTF-8' ? 2 : 4;
for (var i = 0, len = str.length; i < len; i += charWidth) {
var substring = str.substring(i, i + charWidth);
if (charWidth === 4) { // UTF-16, twiddle the bits
substring = substring.substring(2, 4) + substring.substring(0, 2);
}
result += String.fromCharCode(parseInt(substring, 16));
}
result = encoding === 'UTF-8' ? decodeUtf8(result) : result;
return result;
}
(That "twiddle the bits" comment is a bit inaccurate; the technical term is, of course, nibble-swizzling. In the future we will correct this gross oversight by finding some way to work the word "swizzle" into the source code.)
You'll also see us detect UTF-8 vs. UTF-16 encoding like this:
function checkDbEncoding(tx) {
// check db encoding - utf-8 (chrome, opera) or utf-16 (safari)?
tx.executeSql('SELECT dbid, hex(dbid) AS hexId FROM ' + META_STORE, [],
function (tx, result) {
var id = result.rows.item(0).dbid;
var hexId = result.rows.item(0).hexId;
encoding = (hexId.length === id.length * 2) ? 'UTF-8' : 'UTF-16';
}
);
}
In this code, we know based on the length of the hexadecimal string returned whether the database is UTF-16 or not. So thankfully, because it's feature-detected, this "just works" in Safari 7.1+ and iOS 8+.
As of PouchDB 3.1.0, we will also avoid hexing entirely for large binary attachments, because it causes performance problems. The new workaround will be to just remove \u0000 characters while preserving enough information to put them back in later.
IndexedDB, as Web SQL's younger, hipper sibling, is supposed to have native support for Blob objects. In practice, though, Blobs were not supported in Chrome until v37, and assuming Apple fixes the more fundamental problems in IndexedDB, they also apparently will not support them.
In those cases, PouchDB falls back to storing Blobs as base64-encoded strings. And we use feature detection to test it:
try {
var blob = utils.createBlob([''], {type: 'image/png'});
txn.objectStore(DETECT_BLOB_SUPPORT_STORE).put(blob, 'key');
txn.oncomplete = function () {
/* ... */
blobSupport = true;
/* ... */
};
} catch (err) {
blobSupport = false;
/* ... */
}
Ah, but if only it were so easy! It turns out that Chrome v37 also implemented Blob support incorrectly, returning the wrong MIME type when you fetch it. So in Chrome v37, we need to detect the broken blob support, whereas in v38 we can finally start treating it like the other browsers:
var storedBlob = e.target.result;
var url = URL.createObjectURL(storedBlob);
utils.ajax({
url: url,
cache: true,
binary: true
}, function (err, res) {
if (err && err.status === 405) {
// firefox won't let us do that. but firefox doesn't
// have the blob type bug that Chrome does, so that's ok
blobSupport = true;
} else {
blobSupport = !!(res && res.type === 'image/png');
}
});
And yes, Firefox has a tiny bug here as well! Luckily, it's fixed in the nightly build.
So for those keeping score, PouchDB has three different strategies for each of Chrome v36, v37, and v38. And since Android represents different versions of Chromium frozen in amber, all three variations will be out there in the wild for the near future.
CouchDB is one of the grandaddies of NoSQL databases, so unsurprisingly it influenced IndexedDB's design. One of the more useful but tricky features of CouchDB is complex keys, best described by Christopher Lenz:
Obvious to Damien [Katz, creator of CouchDB], but not at all obvious to the rest of us: it's fairly simple to make a view that includes both the content of the blog post document, and the content of all the comments associated with that post. The way you do that is by using complex keys. Until now we've been using simple string values for the view keys, but in fact they can be arbitrary JSON values, so let's make some use of that:
The example given is:
function(doc) {
if (doc.type == "post") {
map([doc._id, 0], doc);
} else if (doc.type == "comment") {
map([doc.post, 1], doc);
}
}
See that? The key is actually an array containing a string and an integer, meaning it would sort first by the string, then by the integer. Cool, right?
This feature is in the IndexedDB spec, and would be a great fit for PouchDB, since we're basically trying to rewrite CouchDB on top of IndexedDB. However, in the source code you will see pseudo-complex keys like this:
docInfo.data._doc_id_rev = docInfo.data._id + "::" + docInfo.data._rev;
var seqStore = txn.objectStore(BY_SEQ_STORE);
var index = seqStore.index('_doc_id_rev');
Leading to gnarly queries like this:
var start = docId + "::";
var end = docId + "::~";
var index = seqStore.index('_doc_id_rev');
var range = global.IDBKeyRange.bound(start, end, false, false);
var seqCursor = index.openCursor(range);
Did we mess up? Nope, it's intentional: we concatenate the strings together, because IE does not support complex keys.
This also heavily influenced our design for persistent map/reduce, because instead of assuming the underlying database can sort by more than one value, we invented a toIndexableString() function that converts any JSON object into a big CouchDB-collation-ordered string. Yeah, we went there.
Update: it turned out I just misunderstood the IndexedDB spec. You can actually swap the start and end in the IDBKeyRange, and that allows you to iterate backwards in all browsers. We updated PouchDB accordingly.
This is one of those wonderful "bugs" that is actually part of the IndexedDB spec, so it's faithfully reproduced in all three of Firefox, IE, and Chrome. I guess we should be thankful?
Anyway, here's the code:
try {
if (start && end) {
keyRange = global.IDBKeyRange.bound(start, end, false, !inclusiveEnd);
} else if (start) {
/* ... */
}
} catch (e) {
if (e.name === "DataError" && e.code === 0) {
// data error, start is less than end
return callback(null, {
total_rows : totalRows,
offset : opts.skip,
rows : []
});
} else {
return callback(errors.error(errors.IDB_ERROR, e.name, e.message));
}
}
In IndexedDB, an error will be thrown for any IDBKeyRange where the start is greater than the end, even if you're iterating backwards. We work around this by manually checking for the end key:
if (manualDescEnd) {
if (inclusiveEnd && doc.key < manualDescEnd) {
return;
} else if (!inclusiveEnd && doc.key <= manualDescEnd) {
return;
}
}
Luckily, this doesn't really have a big performance impact, except that we fetch one more key than necessary.
In both IndexedDB and Web SQL, you can forget about using Promises or even invoking another callback within a transaction. Whenever control is returned to the event loop, the transaction auto-closes.
So although your own PouchDB-using code can be elegant and Promisey (thanks especially to Calvin Metcalf's work on lie), under the hood, PouchDB's own code is pure callback hell.
Here's a taste of our IndexedDB code and our WebSQL code. We party like it's 2009, because you'll see lots of callback patterns like this:
verifyAttachments(function (err) {
if (err) {
return callback(err);
}
/* ... */
});
Or this wannabe Promise.all():
function checkDoneWritingDocs() {
if (++numDocsWritten === docInfos.length) {
complete();
}
}
And if we need to use some other callback API, such as FileReader, we need to be careful to do it outside of the transaction. Hence you'll see functions like preprocessAttachments():
preprocessAttachments(function () {
db.transaction(function (txn) {
/* ... */
});
});
Suffice it to say, if we didn't have extensive integration tests, we'd barely be sure the code worked at all.
Consider this code:
// Unfortunately, the metadata has to be stringified
// when it is put into the database, because otherwise
// IndexedDB can throw errors for deeply-nested objects.
// Originally we just used JSON.parse/JSON.stringify; now
// we use this custom vuvuzela library that avoids recursion.
// If we could do it all over again, we'd probably use a
// format for the revision trees other than JSON.
function encodeMetadata(metadata, winningRev, deleted) {
var storedObject = {data: vuvuzela.stringify(metadata)};
storedObject.winningRev = winningRev;
storedObject.deletedOrLocal = deleted ? '1' : '0';
storedObject.id = metadata.id;
return storedObject;
}
As it turns out, this is a very tricky bug that ended up affecting all browsers, and even Node.js.
The gist is that any native JavaScript function that takes an object as input, such as JSON.stringify() or IndexedDB's put(), has a maximum limit on the depth of the object you can pass in. By depth I mean:
var object = {
enhance: {
enhance: {
enhance: {
/* and so on */
}
}
}
};
The limit itself will vary based on the available memory, but in any case, if you hit that limit, you get a "too much recursion" or "maximum call stack" error. As well as an unhappy PouchDB user.
Calvin and I solved this by writing a non-recursive JSON library with a silly name. It's slower than the native methods, but in cases where we can't afford to have a crash, this code turned out to be a lifesaver.
This is one of those counter-intuitive things that probably made sense to IndexedDB creator Nikunj Mehta, but surprised the hell out of me.
In SQLite and Web SQL, you can create a table with a primary key:
CREATE TABLE employees (id PRIMARY KEY UNIQUE, name);
And you can also add a unique index:
CREATE TABLE employees (id, name);
CREATE UNIQUE INDEX id_index ON employees (id);
And these two are essentially equivalent, because if you try to INSERT a row with an id that already exists, you'll get a constraint error.
In IndexedDB, however, object stores with primary keys will not throw an error upon insertion, but instead silently overwrite the existing object. In other words, the put() is an upsert. Unique indexes, however, behave totally differently and will indeed throw.
Here's a live example. The big takeaway is that the following two examples are not equivalent:
With a primary key:
db.createObjectStore('employees', {keyPath : 'id'});
With a unique index:
db.createObjectStore('employees').createIndex('id', 'id', {unique: true});
Better hope you choose the right one the first time! Otherwise you may get a constraint error when you don't expect one, or vice versa.
Edit: As pointed out by Simon Friis Vindum, you can use add() instead of put() to get a constraint error with keyPaths. Here's a live example. Thanks for the tip!
Databases are not designed in a vacuum, and the more I learn about this stuff, the more I find that everything is related somehow.
Web SQL was originally inspired by Google Gears, which in 2008 was poised to become the standard for storing data in mobile webapps. And of course neither would have been possible without SQLite, which, according to creator Richard Hipp, was heavily influenced by PostgreSQL. In fact, I find his presentation especially inspiring, because Hipp's process of using Postgres as a gold standard for building SQLite reminds me a lot of how PouchDB has been molded in CouchDB's image.
And although the Web SQL spec was eventually abandoned, it certainly influenced its younger sibling IndexedDB. Among other family traits, they share the same asynchronous structure, auto-closing transactions, and security models. (Compare the "security" sections for both specs, and note how much of the language is simply copied over).
Web SQL also lives on indirectly in IndexedDB, given that both Mozilla's and Apple's implementations are independently (!) implemented on top of SQLite.
What's more intriguing is that you can even find the influence of CouchDB in early discussions of IndexedDB. This might explain features like complex keys, start/end key iteration, and the document-esque data model. Nikunj Mehta even said way back in 2009:
Some people find [IndexedDB] good for a JavaScript CouchDB.
In a sense, this statement may be the earliest expression of what eventually became PouchDB!
Furthermore, Google went on to create LevelDB as their implementation of the IndexedDB spec, which is currently enjoying enormous popularity in the Node.js ecosystem, especially thanks to the LevelUP project. PouchDB itself has hopped on the LevelUP bandwagon, and today we have PouchDB Server, which is a nearly-complete implementation of CouchDB's HTTP API, but based on Node.js and LevelDB.
So from the earliest discussions of IndexedDB, influenced as it was by CouchDB and Web SQL, through LevelDB and the LevelUP ecosystem, we now have a database that unites them all: PouchDB.
When I look through the PouchDB source code, this enormous accomplishment still gives me chills. It's enough to make you overlook all the odd hacks, workarounds, and inelegancies. The fact that PouchDB works at all is a tiny miracle.




